The perfect Azure naming convention

This post is the 2nd in the naming convention series . With this post I want to share my approach to naming Azure resources. Why a naming convention is important is already covered by my previous post . However I do believe that some background is required to understand this approach. So, lets dig in.
Naming convention background
A proper naming convention is one of the main methods for building and maintaining Cloud infrastructure as cattle and not as pets. Supporting the transition from the traditional approach of treating infrastructure as pets “unique snowflakes” with names and emotional attachments, to a Cloud native model whereby if a problem with infrastructure is found the infrastructure in question (or its configuration) is “simply” destroyed and replaced (infrastructure as code). This approach is a must to provision and manage the complex and rather large amount of components & configurations the current day Cloud resources are consisting of.
In addition Azure resource names are immutable (meaning that they cannot be changed after creation) and in some cases not reusable for a set period of time (purge protection). So it is crucial to name resources with longevity in mind and to avoid extensive rework and downtime in later stages.
Therefore the purpose of this this naming convention is to ensure resource names reflect a logical structure enabling automation, scripting and Infrastructure as Code to find, read and process this complex and large amount of resources & configurations with as little and simple logic as possible. Ensuring proper performance, low effort maintainability and drift control.
Resource tagging, a naming conventions best friend
By prioritizing automation operators might get into trouble processing resources by their names. Therefore any naming convention should always be implemented in conjunction with a proper tagging strategy . Since most resources can be tagged with up to 50 resource tags which are mutable and are unlike the resource names not subjected to limiting naming rules and restrictions an operator is be able to filter, search, find and process resources based on their tags effortlessly (check out the following screenshot examples). Resulting in a best of both worlds scenario. And of course tagging is the first step to implementing cost management but thats a different story :).
Example: Filtering resources

Example: Search resources

Example: Visual summary view

Naming convention explained
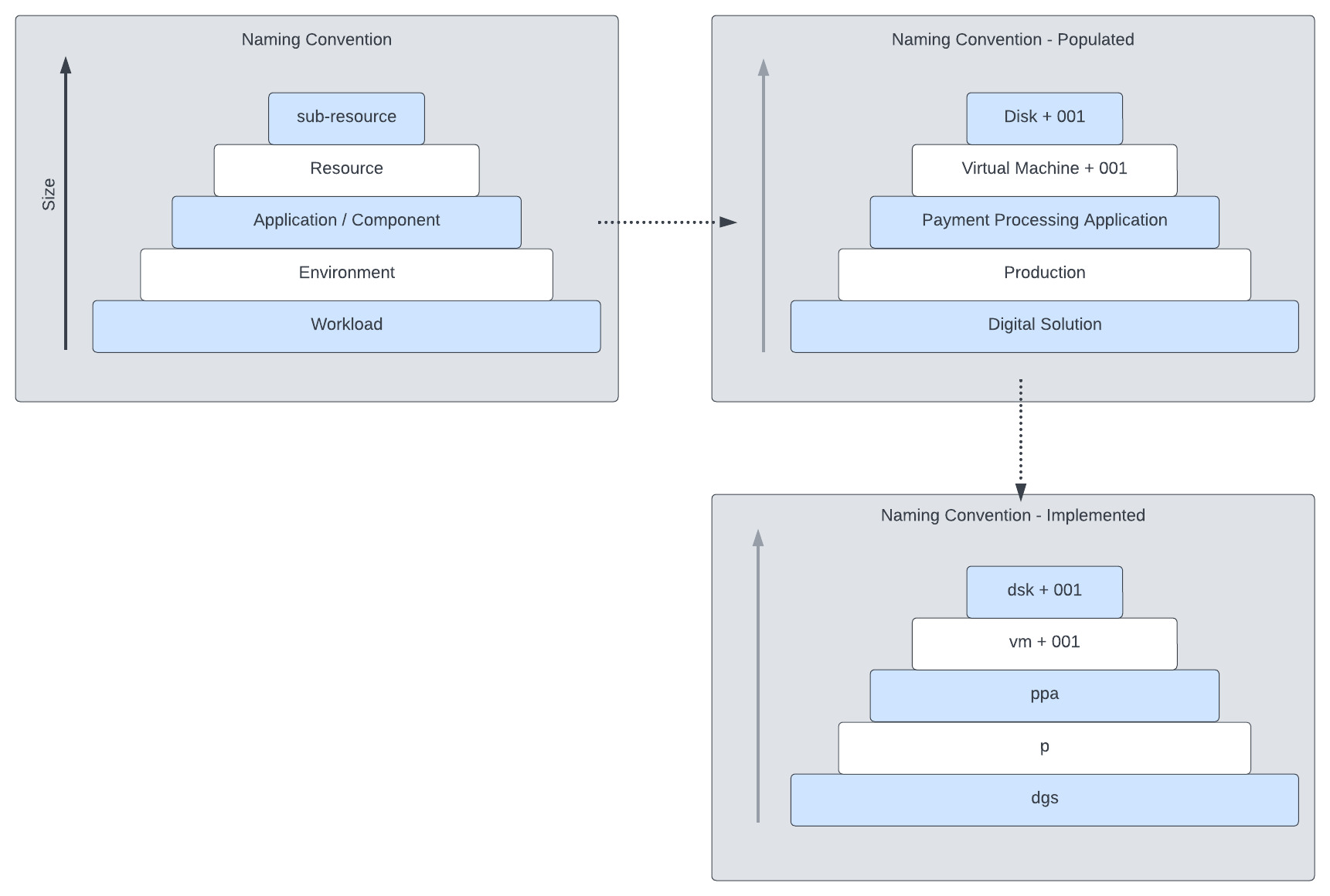
Technically this naming convention arranges components sizewise which also the approach the metric system uses. To visualize this in a clear way for everyone disregarding individual knowledge of sizewise and the metric system , the components are arranged in the form of a stacking doll, a.k.a a Matroska or stacking dolls. Like the ones shown in the next image.

Starting with the biggest component, and moving to an ever smaller component. Up to the point of the sub-resource as sub-resource is the smallest component for this naming convention.
Some sub-resource examples:
- A network card part of a virtual machine
- A disk part of a virtual machine
- A managed identity of a resource
Therefore the region (location) of a resource is not included in the naming convention. And, the region is a field that is present in almost all portal.azure.com views as it is one of the default properties of a resource object.
Simply put: adding the region to the naming convention is overkill.
The order of components (Landing Zone, Solution, workload, application, environment, etc.) and in particular the position of the environment depends on the answers to the following questions.
- What do you consider as a workload?
- What do you consider as an environment?
- What do you consider as a application?
- What is your subscription vending strategy?
How to formulate answers to these questions is topic on its own and deserves a blog post of its own. That said generally speaking there are two common patters;
- Environment as the second component -
<workload-name-affix>-<environment>-<application>... - Application as the second component -
<workload-name-affix>-<application-suffix>-<environment>...
Depending on the scenario either the environment is considered a larger component or the application is considered a larger component. Both are show in more detail in the following sections.
For example, this is how the Matroska naming convention would look like with an environment as the second component in the size wise hierarchy.

And an implemented example would look like the next image. This image is constructed as follows:
- A workload called
Digital Solutions - The
productionenvironment - A
payment processingapplication - Which includes
virtual machine - That has a
network interfacedefined.

Lets go ahead put the above shown example to practice by implementing the Matroska naming convention.
Workload naming convention in practice
When using the Matroska naming convention always try to keep the following common guidelines in mind:
- All words must be in lower case
- With the exception of hyphens (-), spaces and special characters are not allowed
- Where possible, kebab-case should be used. Hyphens can be removed for services where only alphanumeric characters are allowed e.g. Storage Accounts
- Recommended abbreviations for Azure resource types
should be used for the
<service-name-suffix>and<sub-resource-name-suffix>
Environment as the second component
In this example the <environment> is the second component, so the Matroska naming convention definitions is applied as follows:
<workload-name-affix>-<environment>-<application>-<service-name-suffix><instance-number>-<sub-resource-name-suffix><sub-resource-number>
Implementation:
Lets implement this definition step by step. First we note down the definition, then we populate the values in definition and as the last step we convert the values to proper acronyms.
Example:
After completing these steps we can apply it, the result is the example shown in the following image.

Code snippet:
Additional examples
Here are some additional examples of the most common resources and resource containers with the environment as the second component.



Application as the second component
In this example the <application> is the second component so the Matroska naming convention definitions is applied as follows:
<workload-name-affix>-<application-suffix>-<environment>-<service-name-suffix><instance-number>-<sub-resource-name-suffix><sub-resource-number>
Implementation:
Same approach as in the previous example, first we note down the definition, then we populate the values in definition and as the last step we convert the values to proper acronyms. See following image.

Example:
With the 3 steps done we can take the output from the implementation step and apply it, the result is the example shown in the following image.

Code snippet:
Environment Acronyms
To support the above described naming convention the following environment acronym’s are available fo use. These are available in two most commonly used versions. A single letter and a 3 letter one.
Single letter:
Three letter:
Closing statement and further reading
Thanks for reading this post, if you haven’t please check out previous post on this subject and I cant wait to share my next post of this series. If you are interested please check out following documentation from Microsoft on this topic.
- Resource abbreviations
- Resource tagging
- Resource naming -> In my opinion this example naming convention is outdated but the rest is still relevant
- Resource naming rules
- Subscription vending